中文版本见这里。
Recently CRI Middleware updated their latest ACB archives’ format, and they seemed to have updated encryption of HCA files as well. As a result, the old toolsets can do nothing on the updated files. After about 20 hours of research I finally found what they changed on the decryption. Might be the first in the world, again. This is what’s called “highlight moment” in reverse engineering. XD
The final answer is somewhat simple: transform the decryption key, and use the transformed key to initialize the decryption table. The formula is key' = key * ((uint64_t)(k2 << 16) | (uint16_t)(~k2 + 2)) where key is the input key and k2 is a secondary key stored in the higher 16 bits of “field alignment” field, in each ACB/AWB file.
This article is about the way and thoughts of finding this transformation. It is roughly recorded in time order. I hope these materials may help someone in the future.
My result is based on various people’s works. Without thoses pieces, the whole puzzle cannot be completed. So a big thank you for everyone involved.
Be noted again: the contents in this article must not be used for commercial purposes.
* “Decode” in the text below may mean decode after decrypting when applicable.
* Sorry about the broken tenses in the last paragraphs. I was too tired to fix them all.
1. Prelude
As the new game Dragalia Lost (ドラガリアロスト) is released, CRI Middleware revealed their updated audio technology. As for me, a guy who does not play games in the “normal” way, I care about resource extraction more than how it displays in the game. Forward thinking is what I should do as a game developer, and reversed thinking is for the cracker identity (not “cracker” as in “cookie” :P).
This update updates ACB version from 1.29 to 1.30. Although it is a minor upgrade, it brings a trouble that, HCAs cannot be decrypted even with the correct key. It began with an issue created by FZFalzar. When I received the email, I didn’t know or understood what was going on. In the next day, esterTion posted a screenshot of a comment in his blog article, saying that someone is not able to decode extracted HCA with the game provided. I recalled that the key is the one I saw in that issue, so this must not be a coincidence. Together with the information FZFalzar provided, the new tools should have changed something, which might break backward compatibility. I could imagine if the same measure is applied on CGSS or MLTD, or other games, maybe, a doom for audio extraction. So I decided to challenge it.
2. Initial Analyses
2.1 File Analyses
The first thing to do is analyzing the files to see whether there are some “odd” values.
Since I already had an ACB extraction tool (AcbUnzip), I directly dragged the attached ACB on it. Unexpectedly, AcbUnzip crashed, only throwing an exception and creating an empty file. I also tried VGMToolbox, which created 6 files, but all of the files were empty too.
Since I wrote AcbUnzip, I could debug it. I found that the difference of the number of files is caused by the difference of the numbers of cues and tracks. There was only one cue, but there were 6 tracks (3 in internal AWB and 3 in external AWB). But the bigger problem was that, though I had the information of file entries, I could not extract them. The file sizes were negative numbers with extremely large absolute values! After narrowing down by instrumentation, I saw that the value of “field alignment” fields in AFS2 (the file structure used by AWB) was quite strange. According to VGMToolbox, it should be a 32-bit unsigned integer. From the past experience, the value is usually 32. However this time, it was far larger than the file size.
The most common guess should be there is a mask. So I looked at the value in hex digits. The lower 16 bits were 0x0020, which is 32; the higher 16 bits were something unknown. Obviously, it is masked by 0x0000ffff. I successfully extracted all HCA files after doing this.
The exception was the first piece of the puzzle. Besides applying a mask, it also exposed the fact that the layout of AWB had changed. As I said, since the field offset (32-bit unsigned integer) was usually 32, which is far smaller than 65535 (0xffff), its higher 16 bits were actually reserved. Here I began to doubt if CRI did use the higher bits as reserved and attached some other meanings to them. But I still could not determine whether they were random numbers (to disturb analysis) or they do have a meaning.
After the HCAs were extracted, it was time to take a view on them. They looked normal: no unknown header parts or blocks, no out-of-range values, and no additional information added. The only recognizable thing was the size of HCA header extended from 96 (CGSS/MLTD) to 397. But except for known fields, the header was filled with zeros.
Here I made 3 assumptions:
- The actual size of the HCA header can affect the decoding choices of the decoder. You can think it as a hidden version information apart from the “version” field in the HCA header.
comp1tocomp10(referring to the HCA decoder) were set to some meaning values that affect the decoding process. I did not know what those fields mean so I was unable to proof or deduce only by observing.- Nothing was changed. The file was still a traditional HCA.
All these assumptions were possible, requiring more materials to proof or falsify.
At this point, the limit of file analyses was reached.
2.2 Next Directions of Investigation
Just as I replied in the issue, after some observations, considering the updating speed of the technology, iteration cost (time and finance), I thought of 4 most possible possibilities:
- The decoding process was changed.
- New branches were introduced in the decoding process.
- Precomputed tables were changed.
- Real decryption key was different from the input key.
Of course their combinations were also possible in reality. Here let me explain the details of each possibility.
The first possibility. The new decoder employed an entire new theory. This means huge changes in theory and code, which can be seen as a new audio format. CRI should not have enough time and financial support to do this.
The second possibility. Think about the values of comp1 to comp10 mentioned above. Considering known code structure of the public decoder, if new branches were introduced to handle values that never appeared before (in the context of code, if), then new branches or new tables would be logical. I thought it possible, but proving is hard. It depends on the decompiled code.
The third possibility. Since the core of decoding is value mapping using the precomputed tables, could the tables themselves were modified (the code should also be updated) so that input were mapped to different outputs? This thought also depends on decompilation.
The fourth possibility. This is a two-phase encryption. The overall process was untouched but the key was transformed internally, or a decryption table different than the previous one was generated using the same key. Obviously this is the most probable way. All you need to do is adding a few lines of code, and all the public decoders stop working. The cost is close to zero. Combining with the decoding workflow of HCA, in validation, decryption and decoding, a process does not influence the previous one(s). So the key can be easily set to a new one. (By the way, this is also how hcacc works.)
However my guess was that the key was modified before initializing the decryption table. For that I was wrong.
2.3 Initial Feedback
Because I could only obtain a lite version of the SDK (ADX2LE SDK), which does not support encryption and decryption, and FZFalzar had the full SDK (ADX2 SDK), I asked him to start with some tests. While those tests are in progress, I began the initial reverse engineering on tools in ADX2LE SDK.
I had a question above: is the new SDK backward-compatible? It can play the latest ACB, but can it play old ones? Whatever the answer is, it would help eliminate false guesses. My personal guess was the new SDK is not backward-compatible, but the test results disagreed. According to the fact I believed that there was not an all-new all-different decoder and tables were unlikely to change. The greatest change would be adding branches and tables, at most. If we got lucky, it would be much easier.
3. Following Analyses
3.1 Following Analyses of ACB
FZFalzar found out that the SDK cannot play extracted HCAs (not being packed inside ACB/AWB) with correct keys. He thought maybe the something got into the metadata of ACB. So I checked the new structure of ACB using utf_tab. The first apparent change was the update of format version. CGSS uses version 1.23.1, MLTD uses 1.29.0, while this one was in 1.30.0.
From my experience learned from MLTD’s ACB upgrade (compared to CGSS), upgrading usually means adding new tables. Current ACB format can only use a limited number of fields (for easy coding?), so it reserved several slots in the end. CGSS (1.23.1) had 18 reserved slots (R0 to R17), and in MLTD (1.29.0) there were only 12 (R0 to R11). And this time (1.30.0), a new table SoundGeneratorTable was added compared to MLTD. Could this table influence HCA decoding? I thought not. In the sample ACB, the size of this table was zero. If this table is used as a switch, CRI could have chosen a much simpler type. If it is a table and it does have influence, it should not be empty, but filled with some meaningful data.
I did not find other important differences in this sample ACB besides this new table. Some control tables, such as TrackCommandTable, SynthCommandTable and TrackEventTable is not yet parsed, they should not play such row because of their usages in history. To be sure, I modified some values and tested, with no luck.
At this time, FZFalzer sent the player (Atom Viewer, 2.25.14) in the latest full SDK. Finally I was able to test the keys.
During testing, I discovered something interesting. I mentioned before that in the header of AWB there were 16 unknown bits (2 bytes) in “field alignment” field. This time I tried to modify those two “garbage” bytes. I tested these combinations with the new player:
- ACB from CGSS (internal AWB), with no modification. (These 2 bytes were always
00 00in previous ACBs.) - ACB from CGSS, with modification.
- ACB from Dragalia Lost (external AWB), with no modification.
- ACB from Dragalia Lost, modified internal “garbage” bytes only.
- ACB from Dragalia Lost, modified external “garbage” bytes only.
- ACB from Dragalia Lost, modified internal and external “garbage” bytes.
- ACB from Dragalia Lost (internal AWB), with no modification.
- ACB from Dragalia Lost, modified “garbage” bytes.
If the AWB is an external one, the information in ACB will declare that the AWB is a streaming one. Inside ACB it will also store a copy of the header of the AWB. So I thought it was necessary to test both internal and external modifications.
Guess which ones could be played normally? The answer is 1, 3, 4, 5, 6 and 7. Yes, all combinations from 3 to 6 could be played. This was a bit strange but it might be a mistake during test. Now that the decryption is already retrieved, there is no need to test them again. But you can still try it if you like.
The results showed that even ACBs in old versions could not be played with those two bytes modified. So these two bytes must be playing some kind of roles. But where the switch is and how are the bytes involved, were still unknown.
Later FZFalzer tested 2017 version of the SDK (possibly the one MLTD uses) and reported that it could not play the new ACBs. Therefore, the breaking change exists between these two versions.
3.2 Other Simple Trials
Considering that there were 6 HCAs in the ACB, and they were in two groups, members in which were of the similar size. Could they be XORed? I tested this possibility but the answer was no.
What about between groups? Like simple cyclical passwords with short key and long encrypted text? Nope.
How about direct key manipulation? Assuming that those two bytes are used, but none of adding, substracting, shifting or masking worked.
4. Decompiling
All other methods were run out. I had to use the last resort, decompling. Decompling can almost solve all problems, but also with very high costs. It requires massive time, energy, techniques and experience. I was not sure if I can solve the problem before I reach my limit.
The materials i had were ADX2LE SDK (mainly Win/X86) and the APK from Dragalia Lost (Android/ARM32). Later the new player (Win/X86-64) was also used.
4.1 Initial Analyses on Setting the Key
This step began at the same time when I asked FZFalzar to do the compatibility tests. My intention was looking at the usages of the key after it is set. The entry point was quite obvious, the well-known criWareUnity_SetDecryptionKey().
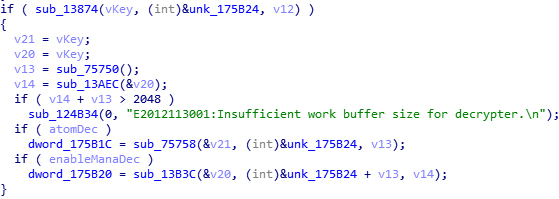
Statically trace to the location above. The first thing we can see is that the input key is not changed during this process. Another noticable point is, the input key, or the original key, has passed the file verification. Now follow the decryption setting of Atom (audio decoding component) to the next level.

Here we run into some troubles. There are lots of global variables and unknown arrays or class members. But by looking carefully you can see that the key is only printed out (to the debug output) here, with some data whose meanings are unknown. If you know a little about the C language, you may have noticed that the call to sub_CEF9C() is problematic. According to its arguments, it should be something like printf_s(), or at least a function with variable arguments. But in the assembly code it is still like this in the picture. The problem is we don’t know what that function outputted. Statical tracing shows the original value of the key is assigned to dword_17AC90, which was not used in the decompiled code. In assembly code, it is set to a register (then its value is assigned to a class member) but not pushed into the stack. Well I can’t get anything more from this, because I don’t know too much about ARM stuff. This lead ends here.
4.2 Analyzing ACB Generation and Reading Processes
FZFalzar mentioned the library CpkMaker.dll in the SDK. He said in the new versions the alignment is set to a large value, while it is 32 unless manually assigned in the old SDKs. Let’s take a look.
Although I don’t have the full SDK, but LE is sufficient for making an impression of code structure. CpkMaker.dll is a .NET assembly, which is out of my estimation. It is written in C++/CLI, apparently. So what are the other libraries that are easy to decompile? From previous exprience I already knew AudioStream.dll is an assembly. From its UI, Atom Craft is obviously a Windows Forms application. With these as an entry point, I found CriAtomGears.dll and AcCore.dll. AtomPreview.dll (who exports some APIs similar to the runtimes of CRI products) and AtomPreviewer_PC.exe are native PE binaries. Managed code for encoding/decoding, or packing/unpacking are not found in these assemblies, so they are definitely inside those native binaries.
Atom Craft has two playback modes. If you import an audio file (which they call “material”) and play it in the Materials panel, it is the audio file itself that is played. But, if you add the audio file into one of the cues, open Session window (in menu View - Session Window), drag the cue onto the list in Session window, and then click the play button, Atom Craft will generate and ACB (content encoding is specified in project settings) and play the ACB file. This difference means behind the different playback handling, there is a invocation from managed code to native code; whether it is P/Invoke or C++/CLI is yet to be tested.
Therefore I try to find the click event. The window name itself is a hint. After painful searches I found it. (I have to say, the code sucks, and assemblies are not well divided.) But the mechanism is not so direct as I think. It uses a C/S architecture. Sending (commands) and receiving (events) are all based on messages. The messaging seems to be wired through sockets. So at run time, Atom Craft starts a native server, and the calls are actually RPCs. As for encoding and packing, it references AudioStream.dll and CpkMaker.dll, inside which the functions are completed using P/Invoke. I have to decompile AtomPreview.dll and AtomPreviewer_PC.exe.
The immediate choice is AtomPreview.dll, because it exposes some APIs. This time, I enter the library from code for ACB to look at the reading process. Well, this is much harder than reading decryption settings. I can only perform three levels of static analysis and the analysis is heavily interfered by class members, so I cannot find something interesting. It is not easy to be dynamically analyzed (can attach to the process though). The code structure is far different from expected and the key signature @UTF is not found anywhere so I don’t know where to start.
Analyzing this from the shared library in Draglia Lost’s APK is as difficult as above.
Atom Viewer in ADX2LE SDK can play the bundle files too. But it does not have public APIs. In the issue comments FZFalzar said the related code is “baked” into the library (in fact this is called static linking :P). Even it does not expose public APIs, there is still a way to locate the code, just make good use of its logs. According to the log, search for string Open ACB: and follow the references. In the end you will find a function with characteristics very similar to criAtomExAcb_LoadAcbFile(). However it is still hard to analyze.
4.3 Analyzing HCA Decoding
Compared to the key settings and ACB, HCA-related functions look harder to catch because they are not exposed anywhere. In addition, the decoding process runs in a background thread, so there is no way to find a direct entry (like from criAtomExPlayer_Start).
Now what? Scan for tiny traces they leak to the surface. Reading the public decoder code, the most impressive thing is those precomputed tables. These tables will lead us to the hidden functions. As a commercial decoder, speed is another important consideration, apart from precision. Sometimes you will have to balance between them. The official decoder is also likely to choose a trading-space-for-time strategy, and it would be even better if they use the same tables. Anyway, try our luck first.
Based on the public HCA decoder, the decoding framework is like:
void decode_block(Block *block) {
validate_block(block);
decrypt_block(block);
for each channel { decode1(channel); }
for (i = 0..7) {
for each channel { decode2(channel); }
for each channel { decode3(channel); }
for each channel { decode4(channel); }
for each channel { decode5(channel); }
}
to_wave(channels);
}
Just have a first expectation in mind. Now let’s see if the official decoder use the same tables.
Here we choose the first element in the second table inside decode5(), 0xBD0A8B04. The reason to choose decode5() is, it lies on the last location in the innermost loop. Its feature serves well as a beacon. As for which table, that is a casual choice. In the worst case just try them all. During searching beware the endianess. Here I use the Atom Viewer from the full SDK (because I prefer X86/X86-64 to ARM), so the search pattern is D4 8B 0A BD.
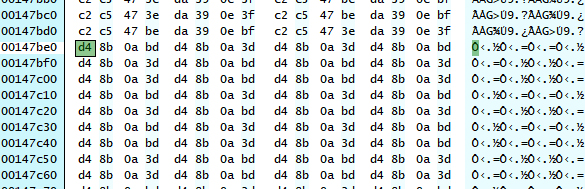

As expected, it is found in the global variable segment. Having a glance at its previous and next elements, it is obvious that this is the table we are interested in. Now switch from Hex View to IDA view and do a xref (cross referencing). Results show that this address is only referenced by one function, whose address is 0x00007FF606770718. Do some more searches on the tables used in this function, we can also find the first table in decode5(). This means the function we are looking is probably decode5() or at least a part of it. The caller of this function contains the third table, and another part of decode5().

Repeating the same operations, find all referenced known tables until the top level of known region is reached. Here is a function decode_block(). In this process you may find multiple references to the same function. Just try them one by one.
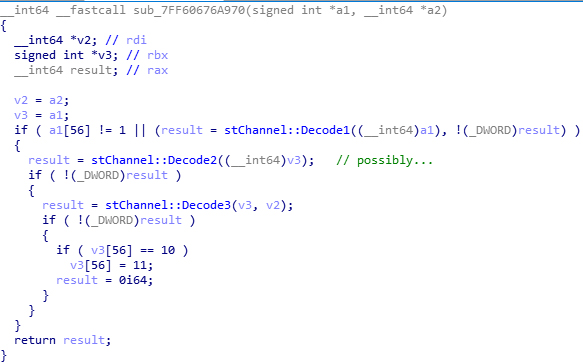
Don’t mind the mild differences of code structure between this and the framework above. The interesting thing is their key characteristics. Keep in mind that compiler optimization is quite powerful.
Again, go up until the top level is reached and there is no obvious caller. Now you should reach a function at 0x00007FF6067688F4. xref-ing shows it becomes a function pointer, which means dynamic invocation, for example registering in a function table or as callback. Inside this function we can find a string literal Failed to decode HCA header., next to which is a function reading the HCA header (located at 0x00007FF60676A274; I name it FindAndLoadHcaHeader because it include some code to search for the offset of the header). Reading the HCA header and audio data block decoding appear inside the same function. What is the function like? Yep, a common (and bad) pattern:
if (flag == PARSE_HCA_HEADER) {
FindAndLoadHcaHeader(pData);
DecodeAudioBlock(pData + headerSize); // Immediately reads the first audio block after reading the HCA header
} else if (flag == DECODE_AUDIO_BLOCK) {
DecodeAudioBlock(pData);
}
Now put that aside. Maybe you will question about the disparity between decode_block() and the public decoding framework. Now let’s check what the code is like in tools in an old version SDK (ADX2LE). Using the same technique to locate the corresponding decode_block() inside AtomPreviewer_PC.exe. It seems the general structures are alike. Forget not, that we are not comparing the decompiled code and the public code, but between old and new versions of the SDK. As there is no (obvious) difference, the decoding procedure should not have changed, and neither should the tables.
Now there is only one question left. What are the meanings of comp1 to comp10 (comp9 and comp10 are calculated using the other comp values)? How do they affect encoding and decoding? Can they take “strange” values? At this time, I suddenly found VGAudio. It was like hitting by a lightning when I read its readme. The shocking fact (to me) is that, the repository includes the principles and details of HCA encoding. There is even an HCA encoder! From this repository I know that those values have fixed meanings, which cannot be, “strange”.
So only one of the four possibilities in the beginning still stands. All of other “hard” (not easily changed) functionalities are unchanged. The key is the only thing modified. But this is contradict to what I discovered above, so there should be something I missed.
4.4 Analyzing Usages of the Key
Finally, the finale. This time let’s trace the criWarePC_SetDecryptionKey() (well, the name is a guess) inside Atom Viewer.
But… isn’t this function not exported? How can we find it? Fear not. We use the same technique as locating from log. The place in criWareUnity_SetDecryptionKey(), where I stuck before, has a variable argument function that could not be understood. There is a format string in that function: %s, %lld, %lld, %s, 0x%08X, 0x%08X, %d, hard-coded. This means in Atom Viewer, there should also be the same, hard-coded string. Open Strings View and search for it. Next step, searching for references.
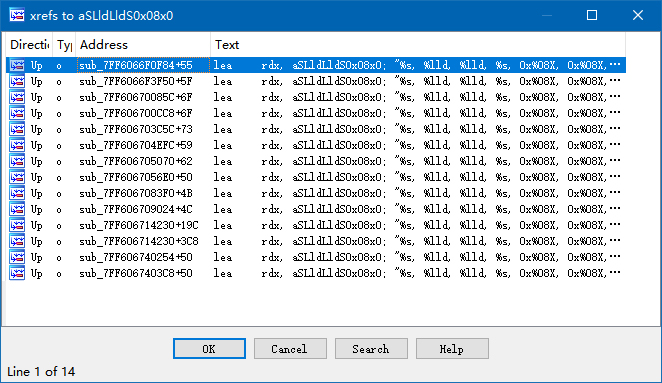
Considering that C/C++ compilers will merge the same strings, it is normal to see such a number of results. A little patience is all we need. Luckily, the first result brings us to the correct location.

The picture above is what it is like after I annotated. But before annotation the high similarity between it and the previous function we analyzed.
Here is a tip. The Hex-Rays Decompiler (F5 in IDA) is not very good a processing variable argument functions. You have to enter that function and exit, to see its correct arguments. (This does not work on ARM. I don’t know why.) After a simple static tracing of one level, most of the symbol names can be deduced. If you are familiar with HCA encryption and decryption, you can pick out InitDecrypter() quickly. Some information requires dynamic debugging, for example finding strings in tables.
Enter InitDecrypter(). A little tracing will show the initialization of type-0, type-1 and type-56 encryptions. The value it returns, according to the log, is “DecrypterHn”, which looks like “decryptor handle”. But if you read it more carefully, you will know that this value is a pointer to the decryption table. This pointer is used by two global variables (one at 0x00007FF606818CC8, another one at 0x00007FF606819628). But neither of these two reveals a meaningful result for tracing.

As we can see, after the normal initialization of this decryption table, it is used as the decryption table for both HCA and HCA-MX. You can confirm the usage name from doing one more xref. So here is where the decoding code analyses and decryption code analyses converge.
I did a simple dynamic debugging. Until setting the decryption tables for HCA and HCA-MX, the contents of the table is still the same as computed using public tools. So there is nothing abnormal until here. But what I am looking for is all references of the key and the decryption table, so I am able to notice this assignment:
v8 = sub_7FF606712670();
*v8 = keyLit2;
Obviously, the key is passed to somewhere else, in addition to the normal usages we see before. Why should this redundant move be introduced?
Expand sub_7FF606712670() and you can see that all it does is returning the address of a global variable:
void *sub_7FF606712670() {
return &unk_7FF606821B30;
}
Where is unk_7FF606821B30 used? Static analysis tells us it is only referenced inside this function. But sub_7FF606712670(), is used at two locations.
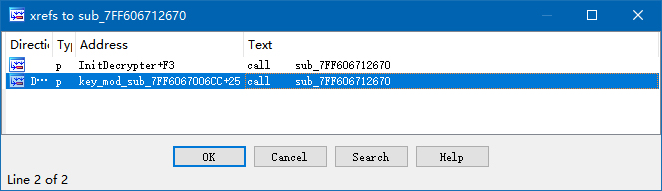
After checking these references, jackpot.

Tracing the pointer v4, which received the pointer to the key, it’s easy to find that it is used in another round of computation, andv6 should be the new key. As expected, the function which uses v6 is for generating a type-56 decryption table. (So why bother writing the same function two times? I don’t understand what CRI guys think.) The problem is how does v5 come from. I add a breakpoint at the assignment of v6, open an ACB, but the breakpoint is not hit. Well, this is an ACB from CGSS. When using an ACB from Dragalia Lost, I get a hit. The value of v5 is 0x80b2, a familar number. I immediately recognized that, this is the two “garbage” bytes inside the ACB/AWB. Although v5 comes from the call result of sub_7FF6066F28C0(), which is the value of a class member, but it is obvious that this is those two bytes. Observing the referencing status of sub_7FF6067006CC(), which is strongly related ACB reading, the inference has a high probability to be a right one.
So I did a little modification to the existing HCA decoder and put in the transformation. And yes, the decoding was successful. Another test on the ACB inside Dragalia Lost’s APK was also successful. Now we can conclude that the reverse engineering this time completed in success.
Let’s read the formula again: key' = key * ((uint64_t)(k2 << 16) | (uint16_t)(~k2 + 2)). key is the input key, and k2 is a 16-bit integer stored in every AWB. Mind the signed/unsigned and length truncation. Also, it does not throw exceptions when the muplication overflows.
If k2 == 0, the key is not transformed. See the decision on v5. For example, esterTion found out Princess Connect Re:Dive also uses ACB 1.30, but the HCAs extracted is still able to be handled by existing tools. This is because the bytes at field alignment is 20 00 00 00.
5. Conclusion
5.1 The Future of HCA Extraction and Decoding
After this update, HCA can use de facto dynamic keys. Directly decoding HCA files using the static keys will not be safe anymore. Batch decoding HCAs are not possible, but it is still doable when having ACB/AWB. It’s just adding another shell. All the tools are still public, and all you need to do is writing a small fix. LOL.
* Update on Oct 16: The vgmstream guys (whose members also watched the issue) already pushed the changes on Oct 14. Wow.
5.2 Some Comments
Well you don’t have to read this in the English version. Just my personal comments.
5.3 The Gain?
To be short, the flexible use of data for attacks. For detailed explanations please read the Chinese version.
5.4 Thank List
Written in the order I think of, when I write this section.
- FZFalzar raising the problem, some experiments, and supplying Atom Viewer
- Alex Barney and his amazing VGAudio
- VGMToolbox from snakemeat
- The anonymous guy who provided the HCA decoder code (ancient code published on 2ch before 2014)
- Everyone discussed in the issue
- And me (:D) (←You already participated in the discussion!