English version can be found here.
近日 CRI ACB 格式更新,连带着 HCA 加密“升级”,旧轮子全员阵亡。在经过二十多个小时的研究后,我找到了关键的修改,搞定了解密。可能又是全球第一个呢。做反向,最激动人心的就是这样的时刻。XD
最终的答案很简单,就是在解密之前,进行密钥变换,并二次初始化解密表:key' = key * ((uint64_t)(k2 << 16) | (uint16_t)(~k2 + 2)),其中 k2 保存在每个 AWB 中的字段对齐的值的高16位。
这篇文章讲的是我找出这个变换的过程,包括思路和操作,基本上按照时间顺序记录。希望在未来会对某人有所帮助。
总的来说,这次的成果是建立在众人的工作基础上,没有这些碎片,就无法拼成完整的拼图。在此要向各位致谢。
再次强调,本文内容不可用于商业用途。
* 下文中,“解码”表示解密(decrypt)之后解码(decode),除非特别指明。
一、起因
随着新的游戏 Dragalia Lost(ドラガリアロスト,中文译名“失落的龙约”)的推出,CRI Middleware 也展示了更新的音频技术。对于我这种不好好玩游戏的人来说,更有意思的不是它在游戏中的表现,而是如何提取资源。正向思考是游戏开发者身份做的事,反向思考是破解者身份做的事。
这次更新带来了 ACB 的版本更新,从1.29升级到1.30。虽说只是一个小版本升级,但是引发了一个问题:即使知道正确的密钥,也无法解密。一开始是 FZFalzar 提了一个 issue。我收到了邮件,但是我并不知道,也没意识到发生了什么。在一天之后 esterTion 在群里发了一个他的博文评论截图,显示有人用已知的密钥也无法解码提取出的 HCA。我看着这个密钥觉得很眼熟,突然想起这不是 issue 里的那个嘛。看来不是个例。结合 FZFalzar 提供的信息,新版的工具确实改变了一些关键的东西,可能无法向后兼容。一想到如果以后烧笋和土豆也更新了那就完了,我决定是时候出手了。
二、初步分析
2.1 文件分析
首先要做的是进行文件分析,看看新的文件有没有什么不正常的地方。
由于我已经有了 ACB 的提取工具(AcbUnzip),我就直接把附的 ACB 拖上去。但是出乎意料地,AcbUnzip 崩溃了,而且只创建了一个空文件。接着我打开 VGMToolbox,它创建了6个文件,然而也都是空的。
那么就没办法了,反正我有源代码,上调试。调试中发现,文件数量的差异是因为条目(cue)和音轨(track)的数量不同,只有一个条目,却有内部 AWB 和外部 AWB 各三个音轨。但是更大的问题是,明明我读取到了文件信息,却无法提取,每次都抛出异常。观察字段的值——文件大小居然是一个绝对值很大的负数!通过逐步插桩确定范围,发现是 AFS2(AWB 使用的文件结构)中的字段对齐被设置为了一个莫名其妙的数。根据 VGMToolbox,这个值是一个32位无符号整数。从过往的文件提取经验中,它一般是32。然而读取后,它的值远远超出了文件大小。
这时候最常见的猜想就是有一个额外的掩码(mask)。于是我看了一下它的十六进制表示,发现低16位是 0x0020,也就是32,而高16位不知道是什么东西。很明显,它应用的是一个 0x0000ffff 的掩码。加上这个处理后,很顺利地就提取出了内部的所有 HCA。
这就是第一块拼图。从这个异常中,除了得知加了掩码这个信息,还可以知道,AWB 的字段意义发生了变化。如我所说,由于字段对齐一般只是取32,远远小于65535(0xffff),所以高16位其实是相当于保留的。这里我就开始怀疑 CRI 是不是将这里看成了保留位,加了私货。但是我还不能确定这高16位是随机数(扰乱分析用的),还是确实有其意义。
解出 HCA 之后,就该观察 HCA 了。不过 HCA 倒是很正常,没有未知块和头,没有超出已知范围的取值,也没有加什么奇怪的东西。HCA 头长度从以前烧笋和土豆常见的96加到了397,但是除了已知字段,其他的部分都是用0填充的。
在这里我有三个假设:
- 实际头大小会影响 HCA 解码器的解码选择。可以认为这是除了 HCA 头的版本字段外,一个隐藏的版本记录。
comp1到comp10(见 HCA 解码器)被设置为了有其他意义的值,影响解码。因为我不知道这些值具体是做什么的,所以也不知道怎么去证明,更无法通过肉眼观察得出。- 其实什么都没变,还是正常的 HCA。
以上三条都只是可能,需要其他材料来证明或者证伪。
到这里就是目前初步文件分析的极限了。
2.2 探索方向
正如我在 issue 中回复的,做了一些初步观察后,考虑到技术更新速度(弱点!)、迭代时间和成本(对于商业公司也是弱点!),我先设想了四种最可能的情况:
- 解码过程改变了。
- 在解码过程中引入了新的分支。
- 改变了预计算的表。
- 输入的密钥和实际使用的不一样。
当然,实际操作中,可以只选一个或多个一起选。这里我解释一下每一条的具体意义。
第一种情况,新的解码器从根本上用了不同的原理。这意味着大型的理论更改和代码重写,基本上可以算是新的格式了。我不认为 CRI 有时间×财力这么做。
第二种情况,结合上面提到的 comp1 到 comp10 的取值,考虑到已知的解码器的代码结构,如果引入对应其他值的分支(体现在代码中,就是 if),可以引入新分支和/或新表。我觉得有可能,但我暂时无法验证。具体要看反编译的代码。
第三种情况,既然解码核心是查表来重建波形,是不是有可能这些表本身发生了变化(同时代码要配合变化),导致查到了不同的值呢?这也要反编译才行。
第四种情况,就属于二次加密了。总体流程没变,但在内部将密钥进行了变换,或者根据了同一个密钥生成了和以前不同的解密表。这显然是最可能的方式,只需要添加几行代码,就能让公开的(带解密的)解码器全部失效,而且几乎是零成本。结合 HCA 的解码流程,验证、解密、解码三者,后面的步骤不影响前面的步骤,所以密钥是可以随便更改的。(这也是 hcacc 的工作原理。)
不过当时我的猜想是密钥在进行解密表初始化之前被变换,这个猜错了。
2.3 初步反馈
由于我只能拿到精简版(lite edition)的 SDK,也就是 ADX2LE SDK(不支持加/解密),而 FZFalzar 有完整的 SDK(ADX2 SDK),所以只能先拜托他来进行测试了。在他开始测试的时候,我也开始对 ADX2LE SDK 中提供的工具进行初步反向。
上面我就有一个疑问,新的 SDK 是不是向后兼容的。虽说可以播放最新的 ACB,那以前的是不是无法播放呢?不管答案如何,这个答案都将十分有助于我排除猜想。我个人的猜测是无法向后兼容。但是其实可以。这就让我确信了,全新的解码器是不存在的,改已有的表也是不存在的,最多就是增加分支和表,运气好的话会更简单。
三、进一步分析
3.1 ACB 的进一步分析
FZFalzar 发现,如果是将 HCA 提取出来,即使输入了正确的密钥也无法播放。于是他猜想,是不是 ACB 的元数据加入了新的东西。我用 utf_tab 查看了一下 ACB 的表结构。首先发现的是格式版本升级了。烧笋用的是1.23.1,土豆用的是1.29.0,而这个的版本是1.30.0。
从我观察烧笋到土豆的经验,升级一般意味着增加新的表。现在的 ACB 能使用的字段个数是有限的(大概是为了代码好写),所以在最后预留了一些字段的位置。烧笋(1.23.1)的还剩下18个(R0 到 R17),土豆(1.29.0)就只剩12个(R0 到 R11)了。这次就相比土豆新增了一张表 SoundGeneratorTable。会不会是这张表影响了 HCA 解码呢?我不这么认为,因为在样本中,它的大小为零。如果只是一个开关,大可不必这么大动干戈,加一个普通的类型就行;实在要是表,而且要影响解码的话,那也不应该是零大小,而是填充一些有意义的数据。
除了这张表,我没有在这个样本 ACB 中发现什么其他重要的变化。虽说一些详细控制的表,比如 TrackCommandTable、SynthCommandTable 和 TrackEventTable 的内部数据意义我并不清楚,但是它们从历史功能上来看就不大可能会影响解码。不过为了保险起见我还是做了一下修改实验,没得到有用的信息。
这时候 FZFalzar 发来了最新的完整版 SDK 中附带的播放器(Atom Viewer,2.25.14)。于是我终于可以测试密钥了。
测试的时候发现一个很有意思的现象。前面不是提到了在 AWB 的头部,字段对齐的掩码问题吗?我就试着修改了一下那两个“垃圾”字节。我用新版播放器测试了如下组合:
- 来自烧笋的 ACB(AWB 内置),无修改(老版本这两个字节一直是
00 00)。 - 来自烧笋的 ACB,修改垃圾字节。
- 来自龙约的 ACB(AWB 外置),无修改。
- 来自龙约的 ACB,仅修改内部垃圾字节。
- 来自龙约的 ACB,仅修改外部垃圾字节。
- 来自龙约的 ACB,同时修改内外部垃圾字节。
- 来自龙约的 ACB(AWB 内置),无修改。
- 来自龙约的 ACB,修改垃圾字节。
如果 AWB 是外置的话,ACB 除了会声明这个 AWB 是流式加载(streaming)的之外,还会存储每个 AWB 的头。所以我认为有必要把两边的修改都测试一下。
猜猜哪些能正常播放?答案是1、3、4、5、6、7。3到6都能正常播放。这个我就觉得有点奇怪了。不过现在想想可能是测试疏漏,中间出现了错误。不过现在已经拿到了解密方法,以后有时间再重新测试一遍吧。
结果表明,即使是老版本的 ACB,如果改动那两个垃圾字节,照样无法播放。这说明这两个字节一定起了什么作用。但是,哪里是控制开关,以及这两个字节参与了什么计算,都还不知道。
后来 FZFalzar 测试了2017版的 SDK(估计就是土豆用的那个),它无法正常播放新版的 ACB。这就说明,功能断层就发生在这两个版本之间。
(这里有一个小插曲。esterTion 比我先收到通知邮件,他在收到之后直接往群里发了邮件截图,并附言“算法修改石锤”。然后 stat 跟着:“再见.jpg”。确实,乍一听这个消息,心里也是会咯噔一下。)
3.2 其他的简单尝试
考虑到这个 ACB 内部有6个 HCA,而且是两组,每一组内大小近似,会不会是做了异或加密?于是我测试将数据部分异或,但并不对。
那么组之间呢?像简单循环密码那样,用短密钥、长密文吗?也不对。
直接对密钥操作呢?假设那两个字节有用,那么做一些加减、二进制操作试试。然而还是不行。
四、反编译
这时候实在是没办法了,只好祭出大杀器,反编译。它几乎可以解决所有问题,但是代价也很大,需要大量的时间、精力、技巧和经验。我不知道能不能在我到达极限之前攻破这个问题。
手上的素材有 ADX2LE SDK(主要是 Win/X86)和龙约的 APK(Android/ARM32)。后来加入了新版播放器(Win/X86-64)。
4.1 初步分析密钥设置流程
这个操作是我在让 FZFalzar 测试兼容的同时开始的。我的目的是看看密钥在设置后的流程。入口点很简单,就是众人皆知的 criWareUnity_SetDecryptionKey()。
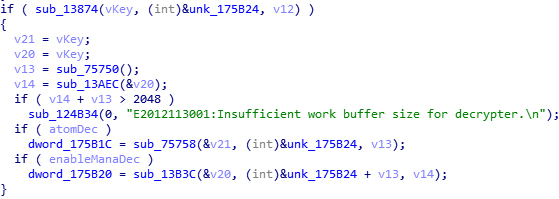
静态跟踪到上图的位置。首先可以看到,设置的密钥在这个过程中是没变的。另外一个值得注意的事情是,设置的密钥,也就是原始密钥,到这里已经通过了文件验证。接着跟着 Atom(负责音频解码)的解密设置来到下一层。

这里就有点麻烦了,一片都是全局变量,还有意义不明的数组或类成员。但是仔细观察一下,密钥在这里只是被打印出来(到调试输出)了;而且同时被打印出来的还有一些意义不明的数据。如果你有一些 C 语言的知识,你可能已经注意到了,sub_CEF9C() 的调用是有问题的。根据输入的参数,它很像是 printf_s(),至少是一个变参函数。但是去看汇编的话……它好像也是这个样子。麻烦的是,我们不知道它输出了什么东西。静态跟踪可以知道,密钥的原始值赋给了 dword_17AC90。但是,在直接反编译的代码中并它没有被使用。去看汇编的话,它被放到了寄存器里(并进一步赋值给了类成员)而不是压到了栈上。这个我就不知道什么意思了,毕竟我不熟悉 ARM 那一套。线索可以说到这里先断了。(当然,根据后来的结果,如果这里进一步挖掘的话,可能可以提早得到结论。)
4.2 分析 ACB 生成和读取
FZFalzar 提到了 CpkMaker.dll,说他能看见新版设置对齐时默认设为了一个异常大的值,而老版本则是默认为32,除非手工设置。那好,去看看。
我虽然没有完整版 SDK,但是只是看代码结构的话,精简版也是可以的。出乎我的意料,CpkMaker.dll 是一个 .NET 程序集。而且很明显使用 C++/CLI 编写的。还有其他这么容易分析的吗?AudioStream.dll 以前分析解码的时候就知道是程序集了。从界面来看,Atom Craft 明显是一个 WinForms 应用程序。以此为入口,又找到了 CriAtomGears.dll 和 AcCore.dll。同时,AtomPreview.dll 和 AtomPreviewer_PC.exe 是原生的 PE 文件;前者可以发现导出了一些跟 CRI 的运行时公开的函数近似的函数。那些程序集都没有托管的编解码、打包解包代码。因此这些功能肯定都是在原生二进制文件中。
在使用 Atom Craft 的时候,我发现,它有两种播放模式。导入音频文件(他们称之为素材,material)之后,直接在素材面板播放,是直接播放素材所指的文件。但是如果将其加入其中一个条目(cue),打开会话(session)窗口(View → Session Window),把这个条目拖放到会话窗口下面的列表中,点击播放的话,则会生成 ACB 之后,播放 ACB 里面的内容(格式视工程设置而定)。这就意味着,在这个功能背后,是一次从托管到原生的调用,具体是 P/Invoke 还是 C++/CLI 那就不知道了。
所以我开始去寻找这个点击事件。窗口名称就是提示。经过痛苦的寻找之后(因为不得不说,这代码写得真烂,而且程序集划分不好)我找到了,但是这背后的机制并没有我想的那么直接。它采用的是 C/S 架构,发送(指令)和接收(事件)都是采用消息。消息传递从实际使用看上去是通过 socket。也就是说,在运行时,它启动了一个服务器(原生),而中间的调用其实是 RPC。至于编码打包,是引用 AudioStream.dll 和 CpkMaker.dll (虽然打包的大部分计算是在托管部分完成的)以 P/Invoke 方式实现的。这就再次逼我去反编译 AtomPreview.dll 和 AtomPreviewer_PC.exe 了。
首选自然是 AtomPreview.dll,因为它暴露了 API。这次我从 ACB 相关的地方进去,看看读取的过程。但这怎么说呢,比那个更困难。静态调试只下了三层,被类成员干扰,没找到有意义的东西;而它又不好被动态调试(其实可以附加进程,我糊涂了)。代码结构和预计的不太一样,也没找到标志性的 @UTF,无法确定真正开始的位置。
龙约里的那个从 ACB 入手也同样分析困难。
ADX2LE 附带的那个 Atom Viewer 也是能播放各种玩意儿的,不过没有公开 API。FZFalzar 说是把相关代码“烘焙”(baked)了进去……其实是静态链接(statically linked)啦。虽然没公开 API,但是还是有办法定位的,只需要利用它在运行时生成的日志。根据打印的日志格式,直接搜索 Open ACB: 然后顺藤摸瓜就能找到,函数特征和 criAtomExAcb_LoadAcbFile() 是一致的。不过一样是很难分析。
4.3 分析 HCA 解码
相比上面的密钥和 ACB,HCA 相关函数看上去是更难抓的,因为它没有暴露出 API;同时解码运行在后台线程,所以无法通过可能的入口点(比如 criAtomExPlayer_Start)找到。
那么怎么办呢?看看这些函数有什么蛛丝马迹是直接暴露在外面的。分析已知的解码器代码,最引人注目的莫过于预计算的那些表了。这些表,就将成为突破口。作为商业解码器,速度是精度之外的一个重要考虑因素,甚至精度有时候都需要与速度平衡。官方的解码器也很大概率会采取空间换时间的策略,如果进一步用的是同样的表就再好不过了。不管怎么样,先试试手气。
从公开的 HCA 解码器可以知道,解码的框架如下:
void decode_block(Block *block) {
validate_block(block);
decrypt_block(block);
for each channel { decode1(channel); }
for (i = 0..7) {
for each channel { decode2(channel); }
for each channel { decode3(channel); }
for each channel { decode4(channel); }
for each channel { decode5(channel); }
}
to_wave(channels);
}
先有一个心理预期。接着开始看看官方的解码器究竟是不是用了同样的表。
这里取 decode5() 里的第二张表的第一项 0xBD0A8BD4。为什么是 decode5() 呢?因为它处于最里层的最末,位置作为一个信标来说很适合。至于选择哪张表就随意了,大不了把每个都试一遍。搜索的时候注意字节序。()我这里开始用的是完整的 Atom Viewer(因为我还是喜欢 X86/X86-64 那一套),所以搜索的是 D4 8B 0A BD。

果不其然,在全局变量区找到了。而且看看前后,就是要找的表。找到之后从 Hex View 转回 IDA View,然后执行引用查询(XRef),发现这个变量被且只被一个函数引用了,这个函数位于 0x00007FF606770718。进一步搜索这个函数中用的表,我们还能发现公开代码中 decode5() 的第一张表。这说明这里很可能就是 decode5()(至少是一部分)。查找这个函数的调用者(也就是上一级),在这个上一级函数中发现了第三张表,同时还有 decode5() 的另一部分。

如法炮制,找到所有被引用的已知表,直到最上层,也就是 decode_block() 函数。其间会遇到一些被多次引用的情况,这时候就逐个试验。
不用太在意代码的结构差异,找到关键特征即可,因为编译器的优化和重排可是十分厉害的。
之后一路高歌猛进,上到不能再上,来到位于 0x00007FF6067688F4 的函数。再往上查找引用,可以发现它变成了函数指针,所以很明显是动态调用,比如注册个静态函数表(不是虚函数表)什么的。在这个函数中我们可以发现一个字符串 Failed to decode HCA header.,顺着就能找到读取 HCA 头信息的函数(位于 0x00007FF60676A274,我将其命名为 FindAndLoadHcaHeader,因为它居然还包括了一段搜索偏移的代码)。读取 HCA 头和解码音频数据块出现在一个函数中,你觉得会是什么呢?没错,就是一种很常见(而且很糟糕)的模式:
if (flag == PARSE_HCA_HEADER) {
FindAndLoadHcaHeader(pData);
DecodeAudioBlock(pData + headerSize); // 没错,紧接着就是读第一个音频块了
} else if (flag == DECODE_AUDIO_BLOCK) {
DecodeAudioBlock(pData);
}
这边先放一放。你或许会说上面这个 decode_block() 函数长得和公开的模型不像啊。那么我们看看老版本的解码是什么样子的。利用同样的技巧定位到位于 AtomPreviewer_PC.exe 的与 decode_block() 函数对应的位置。结果发现从整体来看精简版和完整版在解码上没有什么区别(解密就不用讨论了)。不过别忘了,我们的目的不是比较反编译出的代码和公开的代码,而是去看旧的精简版和新的完整版是否有什么不同,如果有再采取下一步行动。但既然没有不同,就说明解码流程并没有发生改变,甚至表也没有变化。
那么就剩下一个问题了,comp01 到 comp10(其中 comp9 和 comp10 是通过其他值计算出来的)表示什么,会对编解码造成什么影响,是不是可以取“奇怪的”值。这时候我偶然搜索到了 VGAudio。读到 readme 的瞬间,我就像被闪电击中了一样。让我震惊的是,它包含 HCA 编码的原理和详情,而且包含一个 HCA 编码器!你要知道,我一直想知道 HCA 编码是怎么实现的,因为整条工具链就只剩下这个环节受制于人,还用的是通过“取巧”手段(而且对用户来说还麻烦)得到的官方库了。但是编码并不能从解码反推。从它的代码中我知道了这些只有编号的字段的意义(虽然并不能实战,因为我信号处理是渣)。而既然他们有固定的意义,就不会随便取值。
所以现在开始的四种可能性只剩下一种了,也就是其他所有“硬”功能都维持原状,只是密钥发生了变化。但是这和我所见的密钥设置有矛盾,说明我可能看漏了什么。
4.4 分析密钥的使用流程
终于到重头戏了。这次我们来跟踪 Atom Viewer 里的 criWarePC_SetDecryptionKey()(猜测名)。
但是……这个函数不是没有导出吗,怎么找呢?别着急,这里和从日志输出中定位是一样的。在我们前面看的 criWareUnity_SetDecryptionKey() 中,不是卡在了一个变参函数输出无法理解的地方吗?那个函数的格式化字符串是 %s, %lld, %lld, %s, 0x%08X, 0x%08X, %d,而且是硬编码。所以,很可能这里面也会有一样的格式化字符串,而且搜索起来很简单。打开 Strings 视图,搜索这个字符串,就可以看到了。接着就是查找引用。
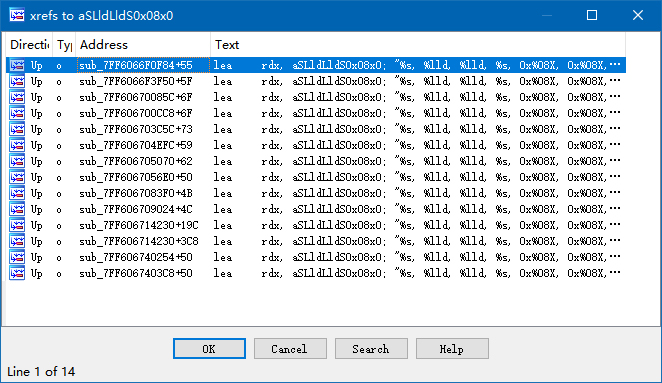
考虑到 C/C++ 编译器会将相同的字符串合并,出现这么多结果也不奇怪。需要的就是一点耐心。不过我们运气不错,第一个结果就把我们带到了正确的位置。

上面这图是我已经标注的样子。不过在标注之前也可以看出和之前我们看的函数的高度相似性。
这里有一个小技巧。IDA 的F5不是很会处理变参函数,需要进入这变参函数再返回,才能看到它分析出正确的实参。(不过这个技巧对前面 ARM 上的并不适用,不知道为什么。)经过简单的一级函数静态跟踪后,上面截图的大部分符号名就能得出了。对 HCA 加/解密熟悉的人也很容易看出 InitDecrypter() 函数。一些信息需要动态调试,比如里面几个查表找字符串的操作。
进入到 InitDecrypter() 内部,经过几级跟踪之后,很容易能看出0型、1型和56型加密的初始化。它返回的根据打的日志是一个“DecrypterHn”,从名字上看是个解密用的句柄(decryptor handle),但实际上仔细看就会发现其实是指向解密表的指针。这个指针被返回后被两个全局变量引用(一个在 0x00007FF606818CC8 一个在 0x00007FF606819628),但是这两个全局变量中,前者除了被设置为 NULL 之外没什么用(意义不明),后者被设置给了一个类成员变量(无法静态跟踪了)。

可以见到,在正常初始化这张解密表之后,它同时被用作 HCA 和 HCA-MX 的解密表——从再 XRef 之后看到的错误信息字符串中就可以看出一个是读取 HCA 一个是读取 HCA-MX 的。解码线和解密线在这里相遇了。
我动态调试了一下,发现直到设置 HCA 和 HCA-MX 的解密表,这张表还是和用已有工具计算出来的完全一致。说明到这里都没什么异常的事情发生。但是我留意的是密钥和解密表的所有引用,所以我自然注意到了这个赋值:
v8 = sub_7FF606712670();
*v8 = keyLit2;
很明显,这个密钥除了在上面我们看到的正常使用外,又传到别的地方去了。为什么要有这个“多余的动作”呢?
展开 sub_7FF606712670(),可以看到它很简单,只是返回一个全局变量的地址:
void *sub_7FF606712670() {
return &unk_7FF606821B30;
}
那么这个 unk_7FF606821B30 在什么地方被使用了呢?静态分析表明只在这个函数里。但是 sub_7FF606712670() 就不一样了,它在两个地方被使用。
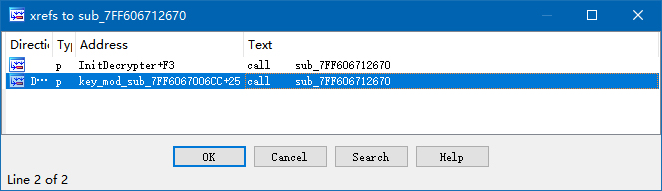
跳转之后就知道,中大奖了。

跟踪收到指向密钥的值的指针 v4 就可以发现它参与了另一轮的计算,v6 就应该是新的密钥。果然,使用 v6 的函数的作用就是第二次生成56型加密表。(所以既然操作完全一样,为什么不用同一个函数呢?不知道 CRI 在想什么。)那么问题就是 v5 是怎么来的了。我在给 v6 赋值的地方下了一个断点,打开一个 ACB,发现没命中。仔细一看,原来我用的是烧笋的 ACB。换成龙约的 ACB 之后,断点命中了。我一看 v5 的值,0x80b2,怎么这么熟悉?由于这两天都在跟这些玩意儿打交道,我立刻意识到,这就是那两个“垃圾”字节。虽然 v5 值的来源是 sub_7FF6066F28C0() 的结果,后者返回的是一个类成员的值,但是很明显,这就是那两个字节。再综合一下这个函数(sub_7FF6067006CC())的被引用情况,它的周围都是 AWB 读取的操作,因此很高概率就是如我所想。
于是小小地改写了一下现有的 HCA 解码器,先硬编码这个值,做个实验再说。结果成功解码了。接着我又试了龙约的 APK 里带的 ACB(装的是音效),也成功了。于是这次反向工作到此结束。
再看一次这个公式:key' = key * ((uint64_t)(k2 << 16) | (uint16_t)(~k2 + 2))。其中 key 是原始输入,k2 是保存在每个 AWB 中的(每个 AWB 内统一的)一个16位值。注意有/无符号和长度截断。此外,溢出是不报异常的,简单向左溢出。
同时,如果 k2 == 0,则不执行变换(见 v5 的判断)。举例来说,esterTion 发现干炸里脊也用了 ACB 1.30,但是以前的解码工具能正常工作,因为对齐的四个字节是 20 00 00 00。
五、结语
5.1 HCA 提取和解码的未来
这次更新之后,HCA 实际上相当于用上了随文件的动态密钥,直接用静态密钥解码 HCA 文件在新游戏中不再保险了。虽说批量解码 HCA 是不可能的,但是给出 ACB/AWB 之后,批量解码又是可能的了。所以只不过是多加了一层麻烦而已,所有工具仍然是公开的,只需要略微改造一下。(笑)
5.2 一些吐槽
SDK 的工具中,提供给反向用的破绽太多了。不仅是代码层面的,还有商业、习惯、理论层面,就看你能不能找到、联系和利用了。虽说一丝裂纹不算什么,但是千里之堤,溃于蚁穴啊。而我最擅长的就是逐个击破。不过或许也可以认为是 CRI 良心,因为要把反向变难的方式多得数不胜数。比如,把静态变量变成单例的类成员,就足以令人抓狂了。如果代码中用更多的动态调用(动态函数表之类)或类成员,或许我就输了。
ACB 头部有个版本字段。但是这次测试中,老版本的 ACB/AWB 只要修改了文件中对应位置的值使次级密钥非零,则密钥还是会被变换,从而导致被修改的老文件也无法正常解码。这个逻辑就奇怪了,按照完全的向后兼容,就该加一个版本判断,小于 0x1300000(也就是之前版本的 ACB)就无论如何也不应该变换密钥。不知道为什么这个正常处理被吃了。
干炸里脊(公主连接,プリコネR,Princess Connect Re: Dive)DMM 版出的时候带了保护。当时正好也遇上群里对通信束手无策,我准备先试试脱壳。结果发现以我的能力,还没到接触到主程序,就已经跪了——虽然已经知道文件内容替换到代码空间,但是 IDA 分析就炸了,因为每次都要重新分析指令。而内存映像又抓不到,我没有 DMM 启动器,进程(在没挂调试器的情况下)在未知的地方崩溃了。还有反调试保护。群里大佬脱了一层,结果发现这是二层壳……最后说是 Android Republic 的大佬搞定了,不过我因为不玩这个游戏,就没再跟进。前几个月有人在我抱怨土豆加密的文章下回复(我觉得应该就是 Crypto 了,虽然穿着马甲)说是被 XOR 了,然而我就没有个 root 过的机子,静态分析又让人崩溃,所以只好不了了之。这次……至少赢了一把。
5.3 有什么收获?
我把这个故事告诉了老爸。他问:“你以前也做反向,这次和以前相比有什么新的贡献呢?”于是我卡住了。
我觉得这次就是一条斜向上的直线,一个台阶都没有。而所谓“台阶”,就是产生了飞跃的地方。上次能吹一会儿的是本地动态库的中间人攻击,但这次好像没有什么新东西。或者换一种问法,这次整个流程中起到最大作用的是什么?
我觉得是解读现有条件的方式。有话云:“看山是山,看山不是山,看山还是山。”原意是建构、解构、重构。大概就是如此。数据,一般都能看出正常的使用方式(读写,换言之,功能是存储);但是在某种情况下,比如这次的作为预初始化了的、紧密排列的全局变量,它的使用状况还可以作为代码的定位工具;定位之后,它又恢复了作为数据的基本功能。就是这样的跳跃,才会打开新的可能性,揭示新的关系。如此的应用总是有条件的,不过试一试总是值得的。
5.4 致谢列表
没必要分先后。按照想到的顺序。
- FZFalzar 发现问题和实验,提供了完整的 Atom Viewer
- Alex Barney 和他神奇的 VGAudio
- snakemeat 的 VGMToolbox
- 提供了 HCA 解码器代码的匿名人士(上古代码,2014年之前发在2ch上的)
- 其他所有参与了讨论的人(有 vgmstream 的开发者马甲在……)
- 还有我自己(笑)(←你不是也参与了讨论吗